

“We cannot make a machine that will reason as the human mind reasons until we can make a logical machine which shall be endowed with a genuine power of self-control.”
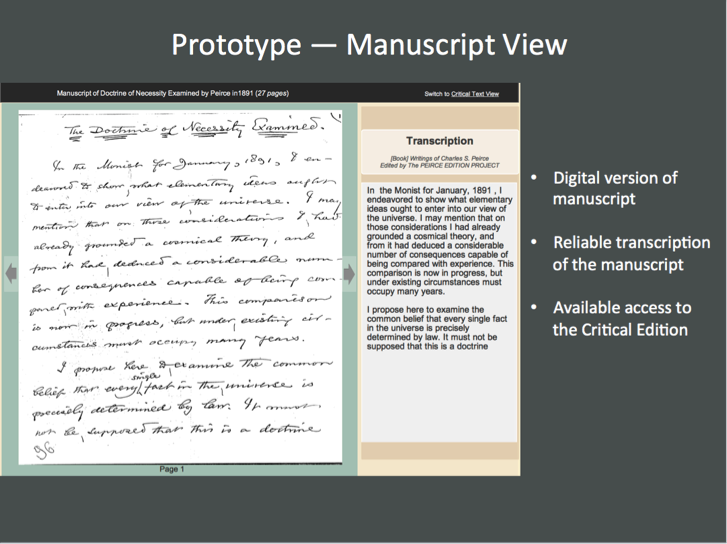
The Peirce edition has reached a crossroad like every other edition. International expectations have much evolved regarding the methods and technical requirements to be followed in the electronic production and dissemination of scholarly editions. Most such editions have been looking for ways to transition from print to digital while also complying with the standards dictated by the Text Encoding Initiative (TEI). While remaining committed to print, the Project has long been developing plans for a different kind of online critical edition. Faced with the need to revamp our technological infrastructure from the ground up in part because XML supplanted SGML as the dominant markup language, we began looking for a cross-platform non-proprietary durable solution, in phase with permanently expanding digital expectations.
One particular demand became overarching in this quest, driven by realism and practical bottom-line considerations. The solution we were looking for must be flexible; easy to use, learn, teach, and implement; and as foolproof as possible to decrease the possibility of transcription and encoding errors. If transcribing a manuscript without tags is already difficult, producing a fully tagged transcription of a complex text riddled with deletions, insertions, and other textual niceties can be extraordinarily time-consuming and confusing. Doing so for thousands of texts compounds the challenge. We wanted something that took care of the tedium while also doing much more.
We examined several solutions, in the US and abroad. Some were alluring, whether proprietary or open-source. Their paragons, oXygen XML Editor, XMLSpy, and others, are versatile, powerful, and support every XML schema language, including TEI. All come with a steep learning curve and so many options that they fail to meet our practicality test, however. It takes time to get trained into them, and even more time to correct the work done with them (validation takes care only of encoding errors and does not reduce real errors that imperil the credibility of rigorous scholarship). One reviewer wrote on the oXygen website that it was “the premier XML editor for geeks.” That is the core difficulty: shoe-string editions cannot afford to hire geeks, who are not good at transcribing texts without committing mountains of errors for lack of the right mindset. Depending on funding, transcribers may come and go, and harried editors can’t afford to fathom how best to anchor tags for days on end. Time being of the essence, training must be fast and intuitive.
What we need, in our distinct profession as makers of critical editions, is a sophisticated tool whose every aspect has been designed from the start to meet our practical typing, tagging, editing, and publishing needs. We have distinct tagging needs in each stage of our production process, from transcription to critical editing to layout, including all intermediary steps for proofing, revisions, and corrections, not to mention all the steps that go into building a comprehensive critical textual apparatus. What we need is a highly customizable tool that conforms flexibly and yet exactly to our practice and workflows, not a tool to which our practice is forced to conform through inevitable compromises and painful workarounds. “Our practice” includes not only the practices in use in the Peirce Project or the IAT editions (each having adapted distinct methodologies to its respective author), but also those in use in other scholarly editions, especially those that handle complex texts: texts that mix graphics with scientific, mathematical, logical symbols, and the alphabets of various ancient and contemporary languages.
Failing to find any comprehensive but specialized solution likely to remain usable across decades, we decided to launch the creation of a new production platform conceived by scholarly editors, leading a team of developers, for current and future scholarly editions. That platform is called STEP, for Scholarly Text-Editing Platform. It also comes with a suite of applications that enhance its usability: STEP Tools.
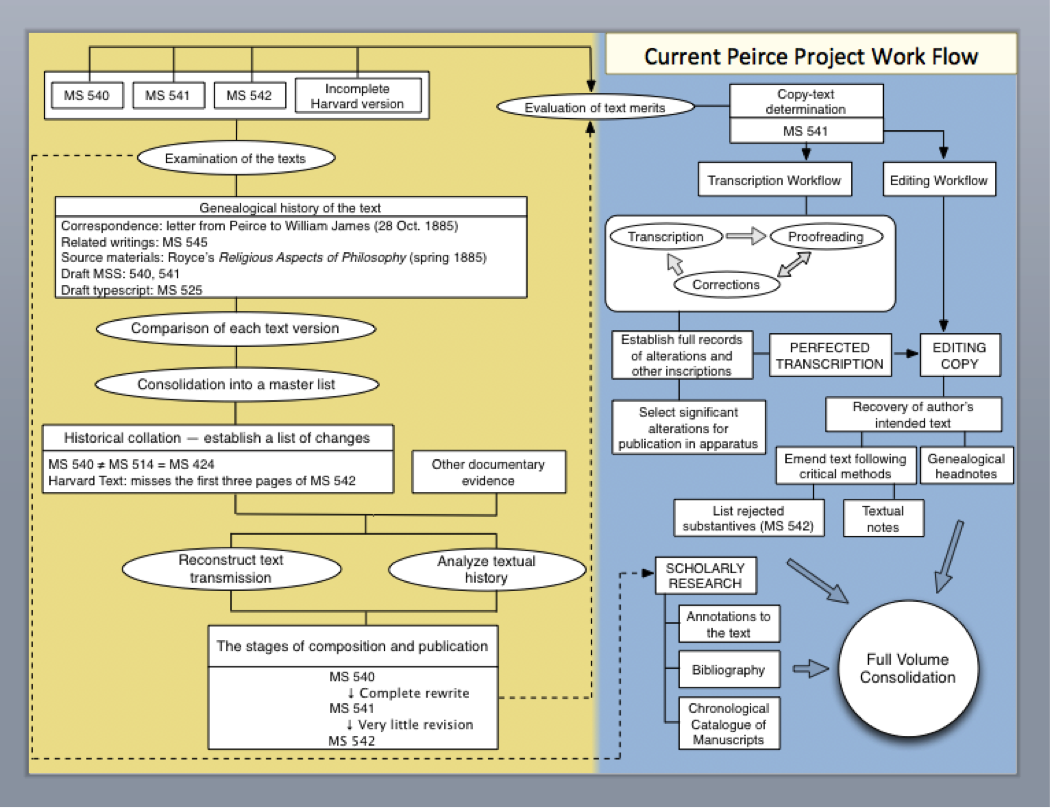
The left yellow section in the chart above maps all the work that goes into organizing a typical set of related manuscripts and figuring out their order of composition. Following that research, the process moves to the blue zone in the chart. A copy-text determination is made, a text is selected for publication in the Writings, and it is sent to initial transcription, thus beginning a long editorial journey that will lead it step by step to perfected transcription, and then through a rigorous critical editing process, followed by sustained scholarly research into its content and construction of the related textual apparatus, before reaching layout stage when all the pieces that are to go into the volume are finally consolidated.
What STEP is about is to provide an online platform that helps take care of all the workflow steps presented in the blue zone above.
Scholarly editors in the 21st century have been redefining their role as trusted agents, mediators, and partners in the advancement of research based on the primary texts of outstanding thinkers and writers. Our overarching goal is to facilitate that professional transformation for the sake of the diverse constituencies we serve. The long-term view makes it clear that it will not be sufficient to merely provide the electronic equivalent of our print editions online, for instance in the form of bland searchable PDFs. Scholarly editions looking for a viable future need to rethink from the ground up both their production and their dissemination methods in the light of the kind of services they need to provide to their growing international constituency, scholarly or non-scholarly.
What is called for is both a reassessment of the fundamental goals of scholarly editions and a reinvention of the very products they contribute to scholarship in a sophisticated digital environment suited for incoming generations. We are convinced that the successful scholarly editions of the future—successful both in terms of ability to attract funding and ability to meet and even exceed user expectations—will be those that take full advantage of advanced contents management frameworks so as to stimulate transformative scholarship while opening it to broader audiences. Critical editions of the future need to view themselves as permanent agents and partners in the advancement of knowledge.
No longer limited to a series of standard volumes collecting dust on bookshelves, digital editions will maintain a vigorous web presence by offering a wide but conveniently centralized array of options to users, including powerful search tools, interactive tools, collaborative tools, work zones, discussion areas, and—especially important for academic users—feedback areas where their contributions get peer-reviewed, assessed, and professionally accredited.
To that end, we have begun designing a dissemination platform, CORPUS (Collaborative Online Research Platform for Users of Scholarly editions). The central idea behind CORPUS is a rethink of what a critical edition ought to be online—what kinds of services it ought to provide or enable. Its main goal is to turn digital editions into interactive online experiences that provide assistance to scholars while encouraging them to contribute the fruit of their own labor and make it available to anyone sharing similar interests. CORPUS also aims to provide the public at large with access to the texts, their apparatuses, and other commentaries while protecting all data from undesirable interference.
The illustration below suggests how STEP is to provide (or feed) CORPUS with a large database of transcribed documents, while both STEP and CORPUS will have access to the same repository of digital images of the Peirce documents. CORPUS itself will be linked with other online resources, journals, research websites, and the like.
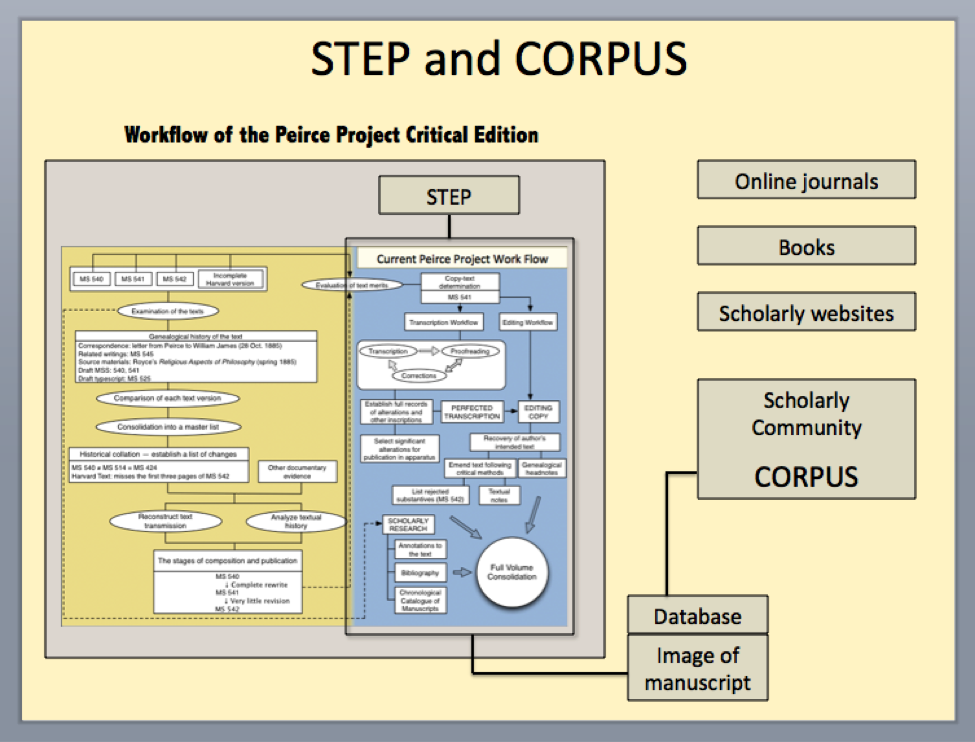
Explore the submenus to the left to learn more about STEP and CORPUS. You will find information about the continuing history of their development, the concepts sustaining their design, the capabilities they will be endowed with, and the specific practical purposes they will seek to fulfill.
“No mind can take one step without the aid of other minds.”
Peirce Project editors began investigating the possibility of an online editing platform as soon as our Montreal partners (PEP-UQÀM) developed their own PHP-based web platform in 2005 to begin researching and producing volume 7 (Peirce’s contributions to the Century Dictionary). That new direction immediately imposed itself as the only viable long-term option for a large-scale project like the Peirce edition. For more than a decade, the Peirce Project had been using Adobe FrameMaker+SGML on Mac OS 9, and produced several volumes successfully. Alas, Adobe ended FrameMaker support for Macintosh computers in 2004. The Project managed to keep running FrameMaker 7.0 on updated Macs with OS 10.4.11 but could not upgrade any further because the newer Mac OS no longer offers the “classic” mode FrameMaker needs. Aging computers elicit the constant worry of system failure. A brand-new long-term solution was thus needed, one that would evolve in lockstep with technology, not only to replace our current system, but also to enhance and complement our editing processes.
In 2009, PEP-UQÀM added to its platform an interface that exported the edited XML text into a format that could be easily laid out in InDesign, but it had weaknesses and could only be used with short pieces of text. They (meaning initially Marc Guastavino, the platform originator, succeeded eventually by Jérôme Vogel) eventually migrated the entire platform to Drupal 6.0, a power open-source CMS framework, and that new platform began to be operative in early 2010. Vogel continued to improve it, until it became a marvel of functionality. Yet it remains a smaller-scale version of the type of platform we envision STEP to become owing to its having been custom-engineered for the making of an extraordinarily complex dictionary. But it was PEP-UQÀM’s project that proved that Drupal would be an excellent CMS framework to build our own solution.
The open-source online Scholarly Text-Editing Platform (STEP) is the generic tool the Project has been designing for several years, in good part thanks to a start-up grant received from the National Endowment for the Humanities, in order to replace obsolescent proprietary software. STEP is to serve as a dedicated online environment for scholarly editors to transcribe, edit, and annotate documents, and publish critical editions in print or online. It is being designed generically so that it can be used not only by the Peirce Edition but also by other scholarly editions with differing needs. The Peirce edition happens to deal with a mass of unpublished texts that are full of complicated mathematical, logical, scientific, and graphical notations. Our calculation is that once STEP reaches a stage that meets the needs of the Peirce Project, it will have a fortiori met the needs of many other scholarly editions implanted in other universities as well.
STEP’s central concept is to provide editors and users with an online XML editor programmed to allow structured TEI-compliant text markup throughout the platform. The larger part of STEP is designed to run online through Drupal 7 and MySQL databases. As discussed further below, STEP will be supplemented and complemented with several tools, some of which are standalone applications operating on individual computers (Mac or Windows), and some as web applications. The collection of those tools is called STEP Tools, a suite of apps designed to work with and for the STEP platform while they can also be used independently of it. STEP Tools consists of TEI/XML compliant tools expressly engineered to take care of the tedium of encoding Peirce’s text and our own critical apparatus according to TEI standards. Nothing comparable to STEP exists in any other scholarly edition: all of our peer editions rely on complex software like oXygen, XMLSpy, Stylus Studio, or other XML editors. STEP and STEP Tools are developed by scholarly editors for scholarly editors; they are meant to be flexible, customizable, and practical tools that do make the life of transcribers easier instead of more complex or forbidding.
When fully completed, STEP will have the following capabilities:
An integrated online TEI XML authoring tool that simplifies the creation process through context-based editing. Its minimal user interface aims to provide only those tagging options (elements and attributes) that are validly available at any current point of inscription within a document based upon its underlying structure and XML schema. Redundant methods of input have been built in to accommodate a range of user preferences. The authoring tool is meant to be used in distinct workflows. It is especially important for the core operation of transcribing documents, which needs to be as error-free as possible.
Exactitude of transcriptions means two things: exact reproduction of the source text, and exact TEI tagging. Exact reproduction depends mostly on a transcriber’s deciphering and typing skills, which are beyond the scope of programming (no spellchecker is allowed in order to preserve an author’s spelling errors). But a well-conceived work area that does not create unnecessary distraction or confusion minimizes typing errors, and STEP has achieved that functionality (not the esthetics yet: the look of the interface will be sharply improved). As to rigor and exactitude of TEI tagging, STEP provides easy access to tags, automatic tag completion, TEI XML validation, and access to TEI information regarding tags. Besides, a special STEP Tool has been created to support transcription: STEP Transcriptor, a dedicated app that specializes in TEI tagging of alterations and also in the application of descriptive TEI tags. STEP Transcriptor also autocompletes tags, but does a great deal more as well, including the automatic production of lists of alterations ready for the apparatus (see STEP Tools).
Versioning, revision, document routing, access control. Thanks to the Drupal framework that sustains STEP, the workflow system that date-stamps and keeps track of each iteration of a document through any particular stage of production is in place. STEP has been set up to save separately each iteration of a document whenever the user clicks the Save button, regardless of its routing stage. Any version may be viewed and reverted back to a previous state by authorized staff. Several categories of users with different levels of read/write access can be preconfigured within STEP in conjunction with the different editorial workflows, and all such features are customizable. Each iteration of a document will come with a routing status that exhibits what stage the document is at within the workflow, who are the users who have it currently on their workbench, and which user or set of users the document will be routed to next.
Highlighting and comments. One important feature is that of linking edited texts and their components to the digitized documents on the one hand, and to their critical editorial apparatus on the other. This is a technically complex undertaking. A digitized highlighting system has been developed that links highlighted portions of a transcription or an image to notes provided by the transcriber—notes that can be anything: descriptions of alterations, emendations, scholarly annotations, special cases of hyphenations, and the like. The types of highlights and colors associated with them are customizable, depending on editors’ needs. They provide ways of annotating textual passages or image segments to indicate different classes of editorial interventions done or yet to be done, or to draw attention to anything in particular. This is a nifty HCI-approved technique, but it eschews TEI XML tagging in favor of long JSON-based XML strings. We are therefore planning to revamp that aspect of the TEI editor while leaving it in place as an option for other editions.
STEP Tools, on the other hand, and at this stage STEP Transcriptor only, takes into account all the TEI rules regarding cross-linking and anchoring apparatus list items with the source text relative to the desired output (print or online). STEP Transcriptor has been programmed to generate and update those complex anchors (complex due to variable attribute and value syntax) automatically. We have therefore acquired a solid understanding of how the cross-linking protocol works, and developed algorithms that take care of it. It will remain to apply this knowledge to both the critical editing module and the annotations module.
TEI XML validation. STEP’s TEI-compliant authoring tool minimizes the risk of creating either non-well-formed XML or invalid schema XML thanks to its context-sensitive editing features and its spare user interface. It also provides immediate visual alerts when non-well-formed XML is manually entered in the editing window.
Upload and management of high-resolution digital images. Digital images of original manuscripts and any supporting images, charts, figures, tables, and other graphics that may be published as part of a given text can be uploaded into the system through the STEP interface. STEP provides a widget that imports images in png, jpg, jpeg, and gif formats and makes them selectable through thumbnails. Clicking a thumbnail brings the corresponding image into a viewport facing directly the transcription field. Manuscript images can be referenced, zoomed in and out, and panned in four directions in the web-browser viewport thanks to tools that slide in and out of view to allow users to mark up image areas. Image areas can be highlighted and have comments attached to them much as if editors had physical copies on their desk, though the highlighted sections and comments are not digitally marked on the image itself to preserve its integrity for subsequent viewings. These highlights and comments can then be viewed and referenced by subsequent editors throughout the editing process.
STEP Tools also provides an app, STEP Image Browser, that allows importing images of a wider range of formats; the import is automatic as soon as an image folder is selected. It, too, provides image manipulation tools.
Streamlining the conversion of copy-texts to fully laid-out and hyperlinked texts readied for online or printed publication. This is STEP’s ultimate goal, and everything we have done goes in that direction. We don’t anticipate many difficulties because of the abundance of XSLT resources, and we count on TEI Boilerplate to be a great source of solutions.
We applied in February 2015 for an NEH Digital Humanities Implementation grant that would help us finish STEP within two years. We requested funding for enough developers, programmers, and HCI specialists to finish STEP and STEP Tools in such a fashion that the world of scholarly editing will have at its disposal a free and efficient platform endowed with a complete set of workflows that move from initial to perfected transcriptions, from initial to perfected critical editing, from initial to perfected apparatus lists, and ultimately from initial to perfected layout, whether that layout be destined to an online digital edition or to a print edition. Such a grant would enable us to accomplish the following goals.
We will finalize STEP’s front-end interface design. Most of the work to date has been in the development of the back-end structure and functions of STEP’s online TEI XML editor (a technical feat) and of the Drupal content and workflow management features. But the interface itself needs to be functionally and esthetically improved. We will use best-practice HCI principles to achieve this goal, with the cooperation of the HCI program in the School of Informatics. This means that usability testing will be at the core of that design, with the input of professionals. The tested user base is international.
We will make STEP’s back-end far more robust by improving workflow settings. One challenge concerns the workflows that move from initial to perfected transcriptions, from initial to perfected critical editing, from initial to perfected apparatus lists, and ultimately from initial to perfected layout. Each of these workflows must be designed to allow editorial staff to fulfill distinct tasks (e.g., recording alterations, entering emendations, creating historical collation lists, marking rejected substantives, producing textual notes, and so on), while tagging the same underlying text (which itself changes over time as it gets emended and edited) without interfering with one another’s work. There are two paramount concerns: avoid the confusion generated by a forest of competing tags, and avoid the danger of overlapping tags, the TEI solution to which is impractical. Our solution is to keep all distinct layers of tags separate from one another for any given underlying text.
The result will be twofold. In the online digital edition, users will have access to each layer (alterations, emendations, etc.) separately without confusion and without being aware that they are looking at different files since the underlying text remains identical. In the print edition, the textual apparatus for each selection will pull its distinct lists from the distinct layers as well, again eschewing confusion. Separating tagging layers will therefore decrease errors by simplifying the tagging and anchoring of complex documents. It will also allow for asynchronous document creation among editors, since the creation of distinct apparatus lists (say, philosophical annotations) will not need to wait for other lists to be completed (say, emendations).
To be robust, the Drupal-based workflows need to be flexible (modifiable task by task) and customizable (adaptable to the requirements of different editions). To solve this, we will design a straightforward administrator interface allowing parameters to be modified on the fly: e.g., variable number of tabs enabling specifiable tasks or classes of tasks, which can be arranged according to an editable workflow that defines task hierarchy, sequential order, responsibility assignment (supervising editors, staff), and access authorization protocols. The intent is to create a few templates and allow users to create other shareable templates.
We will implement a method for transforming the fully tagged perfected documents into print or digital form. This is an essential task, but we don’t foresee this to be overly complicated because XSLT methods are well understood and available.
We will program several STEP Tools beyond those already created (see next submenu).
Before sending that Implementation Grant proposal to NEH, I submitted the entire concept to several sister editions. They all supplied enthusiastic letters of endorsement and support. Here are telling excerpts.
Professor Alois Pichler, the Head of the Wittgenstein Archives at the University of Bergen in Norway, said: “I want to express my strongest possible support for this project because I am convinced that STEP is of decisive value to the field of current and future digital editorial philology… One recurrent problem is … that it takes both editors and transcribers quite some time to acquire sufficient mastery of digital editorial tools such as Oxygen to make the investment in them pay off. STEP is a much needed remedy to that situation…. I enthusiastically embrace Professor De Tienne’s idea of having other projects benefit from STEP development. I myself and the Wittgenstein Archives look much forward to utilizing it for our own work on Wittgenstein and am entirely open for adding a suitable set from our Wittgenstein materials to the project testbed.”
Professor George Lucas, general editor of the Complete Works of Alfred North Whitehead, wrote: “I wish to provide enthusiastic endorsement of the Scholarly Text-Editing Program (STEP) that the staff of the Peirce Edition Project is undertaking. This will be an invaluable tool for handling the flow of digital text and transcriptions for online publication…. I willingly commit myself and our other individual editors to participating with the PEP staff in beta-testing their new program, and insofar as possible, to using it ourselves in our ongoing efforts to produce an authoritative, open, online version of our edition for use by scholars and interested members of the general public without charge.”
Erica Zimmer, from the Editorial Institute at Boston University, testified: “Simply put, the STEP platform revolutionizes both the scope and nature of what scholarly editors new to TEI encoding may accomplish. These twin benefits arise from the ready interface STEP presents between TEI encoding and editorial judgment. … For those committed to editing, it is immediately functional now beyond other platforms with which I have worked…. Broadly, the interoperability this product supports, both in and among projects, appears tremendously exciting for one considering how best to maximize the mutually informing advantages of print and digital insights. Perhaps the greatest compliment I can give the project is the answer [it provides] to scholarly needs I have long felt. Dr. De Tienne and his team have taken extraordinary care to consider how their suite of tools might meet the clear yet flexible needs of users in an evolving media environment.”
It is clear that the technology the Project has been developing answers the real needs of an entire profession, even of those scholarly editions that already have an enormous experience with TEI encoding. Whether or not we get funded, what has emerged is that the Peirce Project can count on the cooperation and good will of many other editorial operations, and that is an enviable position to be in.
“The result is that the ultimately undivided species form a staircase of successive steps. But the steps are not all equal. On the contrary, so thoroughly does twoness permeate the whole that the steps separate into successive pairs.”
“To make [Babbage’s difference engine], it had been necessary not only to contrive new tools, but to lay a scientific foundation of the principles of tools, and to educate the mechanics who were to use them.”
“The great landmarks in the history of science are to be placed at the points where new instruments, or other means of observation, are introduced.”
STEP was initially conceived to be a comprehensive and self-sufficient scholarly editing platform usable in the major browsers. From the beginning STEP development in Drupal 7 followed the principles and protocols of Human-Computer Interaction (HCI) design precisely to foster usability and practicality. Once the online TEI-XML editor was developed, testing showed that it worked well for transcribing relatively simple texts with few authorial corrections. But when it came to complex copy-texts strewn with multiple levels of insertions and deletions, the difficulty and tedium of tagging so many alterations became quickly unbearable on transcribers, just as they had experienced with oXygen. Over time it became evident that STEP could be comprehensive but not self-sufficient.
TEI encoding is not for the faint of heart, if it is to be done correctly—and STEP wants to make TEI encoding exact, not exacting. And so arose a new complementary technological strategy, to answer the pressing need for specialized tools that would alleviate the tedium, automatize complex tagging procedures, and decrease errors. The imperative to retain personnel required that specialized tagging tools be programmed in such a way that users would be spared to the largest extent possible the labor of tagging textual elements (including attributes and values) and anchors. It also became clear that programming such specialized tools would require a keen understanding of the tasks to be performed. Take for instance the following 14 requisites for an adequate TEI-XML transcription tool adapted to the daily grind of scholarly transcribers.
Ready availability of alternative options for entering TEI tags and attributes: pull-down menus, pop-up menus, clickable buttons, autocomplete features, self-correcting features, keyboard shortcuts, programmable function keys, connection to online TEI documentation, and access to examples.
The flexibility to import XML documents from the STEP platform into the specialized tool, together with the option to import untagged or semi-tagged transcriptions from any other source.
Ways of tagging multilevel alterations (say, a phrase deleted and replaced five times through superimposed deletions and insertions) through tag nesting without having to type any angle bracket.
Ways of tagging complex transpositions, including their special TEI attributes and anchors.
Automatic tagging and anchoring of deletion, addition, and damage spans.
Easy ways of inserting special characters with diacritical marks, foreign characters, symbols, unusual punctuation, fractions, in automatic HTML code.
Automatic administration of all TEI-approved anchoring systems, using correct syntax.
Automatic generation of syntactical descriptions of alterations based on their tags, attributes, and anchors, in good English.
Automatic generation of pragmatic descriptions of alterations, ready for the critical apparatus, also based on an intelligent translation of tags and attributes.
Ability to change and customize all aspects and features of the tagging tools, including the assignment of colors to distinct classes of tags, the arrangement of tags within pull-down menus and pop-up menus, the addition or deletion of tags, attributes, and values within those menus.
Ability to export any content of any field associated with the tool either to the STEP platform or to any other text or browser software.
Ability to view the tagged transcription in run-on or indented view, with or without anchors or tags.
Ability to completely separate the tagging of authorial alterations from the tagging of descriptive elements in order to achieve tag clarity while avoiding the scourge of overlapping tags.
Ability to consult a digitized image of the source text on screen while transcribing.
The STEP platform implements several of those requisites partially or fully, but not all: those requiring sophisticated programming (such as c, d, e, g, h, j, l, m) are not within its manageable reach. It occurred to us that all of those requisites could be programmed externally far more efficiently than within the browser interface, and that it was actually appropriate for some particularly complicated or tedious STEP tasks to be performed outside the platform if we could establish a safe protocol of two-way data transfer between the platform and the external tool. From the standpoint of transcribers and users, it is immaterial whether the software they use is an online browser, a web app, an app within their workstation, or a combination of the two, as long as it is convenient, practicable, and advantageous.
What mattered, therefore, was to find a way of programming those complementary tools (or apps) fast, efficiently, using a web-aware, open-source, community-supported, cross-platform programming environment compatible with online browsers, excellent at text and data processing, capable of communicating with other applications, of launching them, of opening, reading and writing processes, and of executing shell commands. Several options were considered but in the end we chose one that was most appealing for its power and reputation for ultra-rapid development: LiveCode, a software developed by Runtime Revolution (aka RunRev), a company based in Edinburgh, Scotland. A cross-platform programming environment, LiveCode is an IDE for creating software deployable to mobile platforms (iOS and Android) as well as desktops (Mac, Windows, Linux). In 2013 RunRev turned LiveCode into an open source development platform, which includes the entire code base for all platforms, including the development environment and documentation. In 2014 LiveCode refactored its engine and integrated Unicode into it, so that LiveCode 7 supports complex scripts, Asian languages, right-to-left and bidirectional text.
LiveCode recently launched an ambitious initiative that bodes well for STEP and CORPUS: the company began compiling the LiveCode engine to JavaScript so that LiveCode apps may also be deployed into modern web browsers, using HTML5 to avoid the need for browser plugins. This means that within two years or so, STEP Tools users may well not need to install any external software because STEP Tools will be inside STEP’s browser-based platform. STEP Tools itself will then be platform agnostic, while its development into either a native app or a browser-based app will continue to be possible from a single code base. LiveCode programming is based on a high level fourth-generation scripting language that is English-like and thus highly readable and easy to debug. It is 3 to 4 times faster to develop a software in that language than in Java. Understanding another programmer’s code in that language is unproblematic. Software can be easily shared with everyone, which extends the open-source concept from specialists to non-specialists.
Having adopted LiveCode, we began developing “STEP Tools,” a suite of STEP add-ons designed to augment the platform with specialized TEI encoding systems. A STEP tool is not a plugin but a full-blown app. Although the initial idea was to simply prototype each tool so that it could be programmed later as part of STEP, the first prototype instantly turned into something functional precisely because it was done in LiveCode. From that point on, the application took a life of its own, and in barely three months “STEP Transcriptor” was born, the first of a suite of tools. STEP Transcriptor’s virtue is that it satisfies all 14 requisites listed above, from (a) to (n). It is a comprehensive TEI-XML compatible solution specialized in and focused on the act of transcribing. It is designed to improve transcriptions begun in STEP or to start a transcription from scratch.
STEP Transcriptor’s main interface in Example mode (Mac view)
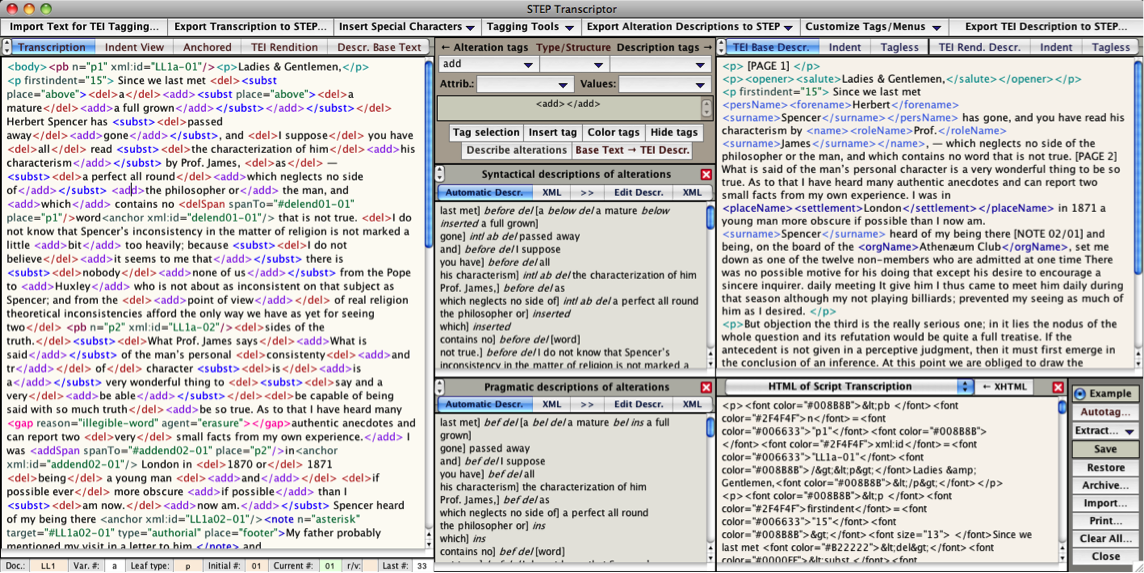
As intimated in requisite (m), STEP Transcriptor makes a sharp distinction between purely transcriptive tags and descriptive tags. It is one thing to tag an author’s insertions, deletions, marginal notations, and suchlike, that is, to create a tagged record of an author’s inscriptions, and quite another to mark up that text in order to identify its syntactic and semantic structure. The latter is a work of textual analysis requiring both a different set of competences and especially a different working mindset. Tagging alterations and other inscriptions as inscriptions is one thing, tagging proper names, bibliographical references, place names, etc., is quite another.
It is not desirable that both sets of tags be entered inside the same file. It creates nightmarish confusion as soon as the text offers any level of complexity. For one thing, it becomes difficult to see the text and proofread it because of the profusion of tags. For another, tags will need to overlap, which is forbidden in XML files. Techniques to work around overlaps are dreadfully complicated, a huge waste of effort, and a boundless source of errors. It is therefore preferable to keep the two tagging activities separate.
STEP Transcriptor offers that separation of activities. The left side of the interface is reserved for transcriptive tags, and yields automatic lists of alterations ready for a critical apparatus. The right side is reserved for descriptive tags (the word “descriptive” being broadly understood). Transcription tags come with the benefit of having STEP Transcriptor generate lists of syntactic and pragmatic descriptions of alterations automatically both in regular text form and in TEI-XML form.



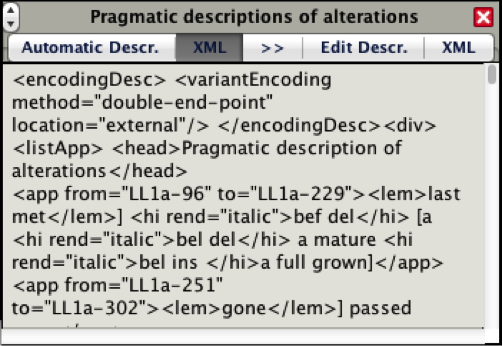
STEP Transcriptor’s automatic alterations descriptions in Example mode (Mac view)
STEP Transcriptor is all about preserving the mental health and inner joy of TEI transcribers. The “nested alteration tagging tool,” aka “stacked alteration tagger,” is designed to remove the anxiety of dealing with complex sets of insertions and deletions nested within one another. Tagging those intricate inscriptions (monuments to an author’s hesitations) correctly is equivalent to the art of nesting multiple sets and subsets of parentheses within logical formulas or software algorithms. The chief notational difference here is that opening and closing tags replace parentheses. One way of getting out of the problem is by cheating one’s way out of it: one simply describes each alteration component independently of each other one, one at a time. But this fails to capture or do justice to the complexity of multi-level deletions and additions. STEP’s answer to the problem is the utility shown below. It is called by choosing the first command, Nested Alteration Tagging Tool, under the Tagging Tools menu button in the top center of the window.
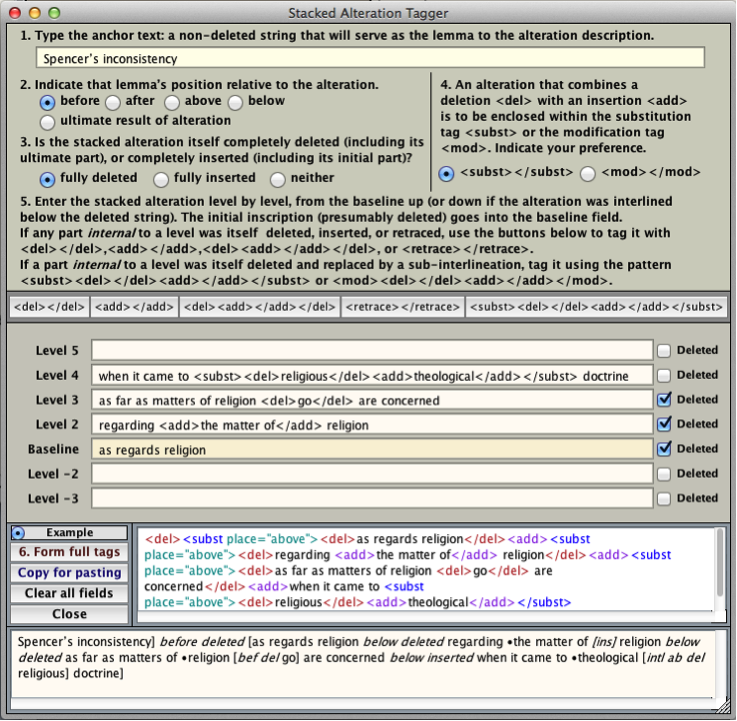
STEP Transcriptor’s solution to encoding nested alterations in Example mode (Mac view)
Another powerful tool in STEP Transcriptor is the Transposition Tagging Tool. It is called by choosing the second command, Transposition Tagging Tool, under the Tagging Tools menu button in the top center of the window. This brings up the impressive-looking, fully self-explanatory window below.
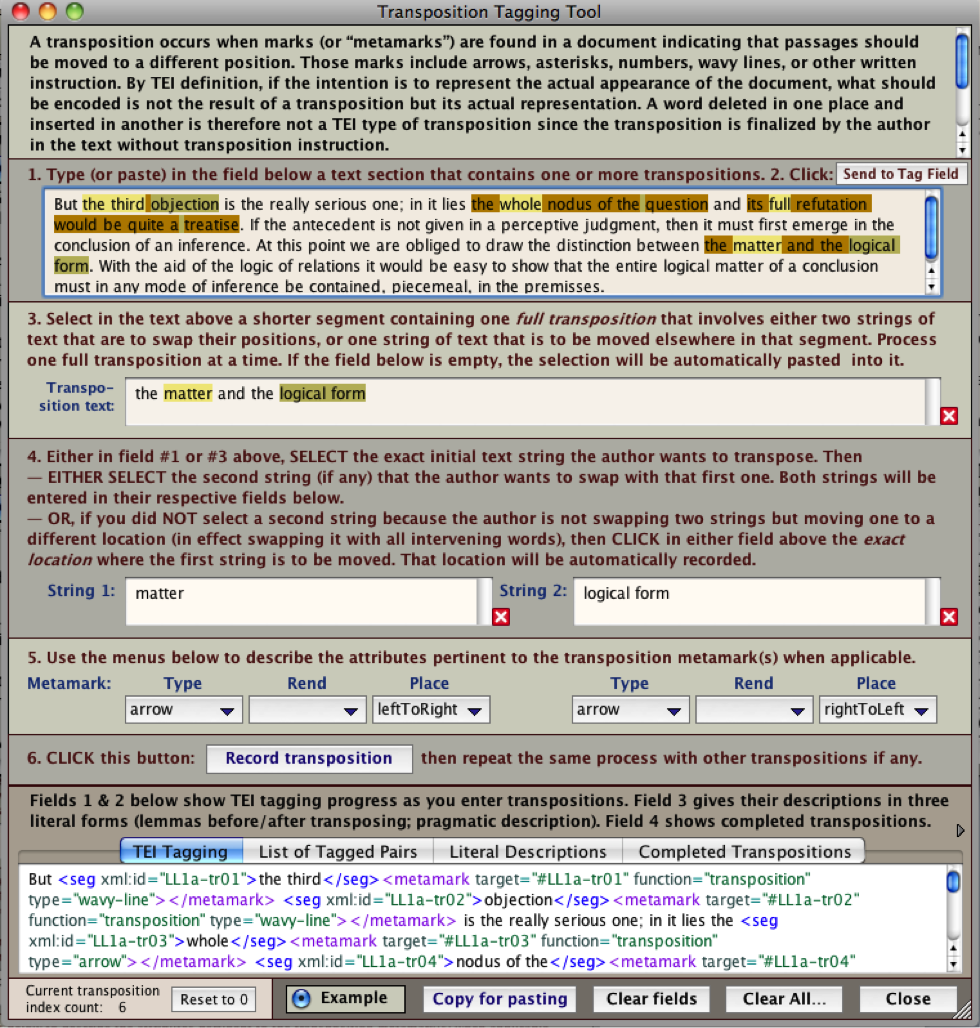
STEP Transcriptor’s solution to encoding transpositions in Example mode (Mac view)
Each time a transcriber uses the window above and clicks the “Record transposition” button, four beneficial operations ensue, each accessible by clicking one of the four buttons just above the bottom field.
All transpositions are fully TEI-encoded in the “TEI Tagging” field, along with the record of their positions inside a <ListTranspose> tag.
Each pair of transposition tags is displayed separately in the “List of Tagged Pairs” field for easier check and correction. That list is also the basis for their literal description.
The field labeled “Literal Descriptions” offers no less than three distinct English-language renditions of the list of transpositions, to accommodate the house styles, preferences, or practices of different scholarly editions, including descriptions with lemmas showing readings before transpositions, descriptions with lemmas showing readings after transpositions, and pragmatic descriptions.
The field labeled “Completed Transpositions” shows the text with all transpositions executed.
STEP Transcriptor is fully customizable. Users can add and remove tags, attributes and values at will with direct access to the TEI website. Users can assign every operation and tag sequence to keyboard shortcuts and function key shortcuts. Users can customize the content of pull-down and pop-up tag menus. And users can customize the colors of tags in order to improve their readability and visual discriminability.
For more information about STEP Transcriptor and its functionalities, and also about other STEP Tools, please download the STEP Tools User Guide.

We do not intend to build a “STEP Collator” tool because satisfactory solutions already exist (e.g., Juxta). But we have developed STEP Text Comparator, a STEP tool that can be used along with STEP Emendator to the extent that emendations rest in part on the collation of variant texts and the adoption or rejection of substantive variations in post-copy-texts. The text comparator helps visualize differences between two texts at a time, in either direction, on the basis of three distinct ranges of comparison: by word span (from 2 to 8 words at a time), by sentence segments, and by full sentences. STEP Text Comparator provides ways of visualizing differences among texts that go beyond text comparators available online (all of them based on a partial grasp of the diff shell command; STEP Text Comparator does not rely on diff). STEP Text Comparator automatically generates lists of differences in which the lemmas come from the base text, and the glosses represent the readings from the variant texts. That utility will be further improved thanks to more powerful text-analysis tools recently made available by LiveCode, the IDE used to develop STEP Tools.
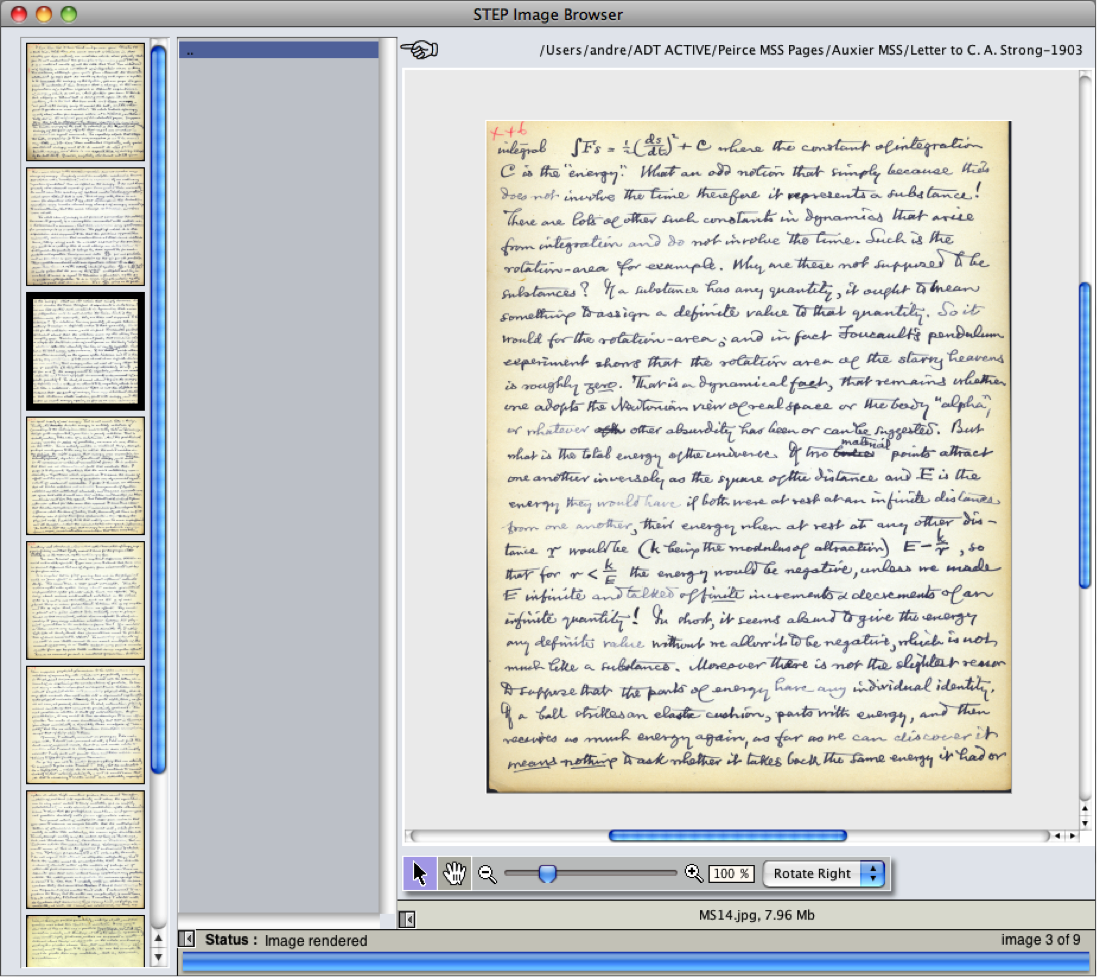
STEP Image Browser is a tool that can be used along with any of the other tools (it can be made to float above them); its function is to provide visual access to digitized images of manuscripts, for transcription, critical editing, or annotation purposes.
By default, STEP Image Browser opens the Documents folder (Mac, Windows) or the Home folder (Linux). Folders in that directory will be automatically listed alphabetically in the scrolling field between the thumbnails area and the image-viewing area. Clicking any folder in that field opens it and, if there any images inside that folder, the image browser will instantly look for them, turn them into thumbnails, and show those thumbnails in the column on the left side of the browser. The image browser will load immediately any JPG, PNG, or GIF files. It will also, on the Mac, locate, convert to jpeg, and show image files with any of the following extensions: .tif, .jp2, .pict, .psd,.qtif, .bmp, .sgi, and .tga.
We are planning to build STEP Emendator (to accompany STEP’s critical editing workflow), STEP Annotator (to accompany STEP’s annotations workflow), and STEP Formulator (to accompany any STEP workflow).
STEP Emendator (already prototyped) is a priority. It will give textual editors a customizable tool letting them emend a text, anchor emendation tags, generate lists of emendations, and create textual notes, without having to type a single tag. The tool anchors each emendation with its complement of lemmas, sigla, and glosses automatically. The prototype is shown in the STEP Tools User Guide downloadable above. Look under “Editing Manuscripts” in the Methods menu to understand what emendations are.
STEP Annotator is another priority and we have begun prototyping it. Editors and specialists often generate a large number of annotations expressly crafted for the critical edition before it appears in print or online. They include scholarly commentaries about the content of the text, bibliographical references to quotations or paraphrases, identification of proper nouns, clarification or explanation of anything that puzzles interpretation, cross-references to other texts, connections with the secondary literature, and so on. STEP Annotator is designed to help scholarly editors manage the drafting, editing, tagging, and selection of annotations, and to make available resources that include archives of past annotations, specialized proper nouns thesauri, previous bibliographical lists, and the like. It is worth noting that since annotations created within STEP are internal TEI-XML data, their structure is ungoverned by the W3C Open Annotation Community Group Data Model, which is concerned not with the creation of annotations but only with a standard description mechanism to share them between systems. The Data Model will thus only come into play in Phase 3, when STEP’s TEI-XML texts are moved to a platform like CORPUS. At that point, maps will be used to allow external systems to retrieve the relevant TEI-XML annotations and assemble them into the Model’s suggested format. CORPUS will provide annotations tools for outsiders to use, but CORPUS will always distinguish between accredited and unaccredited materials: that distinction is vital for scholarly credibility.
STEP Formulator is the third tool on our workbench. It aims to facilitate LaTeX encoding of formulas and their integration within TEI-XML tags. That tool will not reinvent any wheel, for it will rely on existing LaTeX editors. The main goal is to make LaTeX less forbidding for the sake of transcribers’ sanity.
“The Player should bear in mind that the higher weapons in the arsenal of thought are not play-things but edge-tools.”
“We individually cannot reasonably hope to attain the ultimate philosophy which we pursue; we can only seek it, therefore, for the community of philosophers.”
“Now you and I—what are we? Mere cells of the social organism.”
As explained in the Technology Overview that summarizes our technological efforts, CORPUS is essentially an evolving reconceptualization of what scholarly editions can become when they are ported online: not a mere searchable digital version of a book, but an active community of inquiry that welcomes serious researchers on the one hand, and the general public on the other. Whether on paper or online, critical scholarly editions seek to reconstitute and establish with rigorous exactitude and extensive evidence the texts of seminal writers and thinkers, and to produce reliable publications destined to become the common standard of reference for all scholars long in the future. Online editions, however, can avail themselves of technologies that allow editors to redesign and reinvent the very concept of dissemination. Print publications are one essential component of dissemination. But online dissemination can be something else altogether, offering a range of experience that usefully complements and supplements the research and study possibilities already afforded by hardcovers.
CORPUS is the dissemination platform we have begun designing and prototyping with the help of the Human-Centered Computing Department of the IUPUI School of Informatics and Computing. CORPUS embodies a rethink of what a critical edition ought to be online by reexamining the kinds of services it ought to provide. The aim is to turn digital editions into interactive online experiences that provide assistance to scholars while encouraging them to contribute the fruit of their own labor and make it available to anyone sharing similar interests. CORPUS also aims to provide the public at large with access to the texts, their apparatuses, and other commentaries while protecting all data from undesirable interference.
Here is a set of five missions CORPUS is to fulfill:
It will provide the public at large with electronic access to the content of our critical edition and extra materials along with sophisticated search and navigational tools.
It will provide an interactive interface allowing scholarly users to conduct research both publicly (in collaboration with others) and privately.
It will provide users with different levels of privileges allowing them to enhance the electronic product with their own scholarly contributions, such as supplemental textual annotations, cross-references, hyperlinks to the secondary literature, commentaries, targeted links to relevant webpages, etc.
It will provide everyone with access to digital images of Peirce’s papers eventually cataloged in and made accessible by the Digital Peirce Archive, a platform that will authorize users to contribute metadata to that database.
It will institute a quality-assessment system that keeps track of all contributors, gauges the quality of their contributions, protects the system’s integrity to guarantee a safe and productive scholarly environment, and offers peer-reviewed certifications that scholars can use as evidence of their professional worth for instance in P&T dossiers or grant applications. The main goal of that dissemination platform is to stimulate transformative scholarship—a core funding requirement of private and public funding agencies.
As to this fifth aim, there has been an enormous amount of discussion across the nation’s universities regarding digital scholarship and its impact on promotion and tenure standards and processes. The continuing evolution of digital tools and dissemination media keeps broadening the channels through which the products of scholarship get published, while also diversifying the very form of those products in ways that were not envisioned even recently in terms of content presentation and interactive communication. This poses a continual challenge to the peer-reviewing and assessment standards and methods used by academic institutions to evaluate their faculty, especially as the central exigency is to secure and preserve excellence. Any accreditation and assessment system implemented in a platform such as CORPUS needs to be designed so as to offer the highest guarantees of credibility to institutions.
Online scholarly editions offer a large range of fruitful and meaningful interactions with their users, whether academically established or not. They include access not only to authorial texts that have been edited according to highest standards, but also to a vast editorial apparatus. That apparatus includes such components as follow:
digitized images of manuscripts;
variant and draft texts that are part of the textual genealogy of the published manuscripts;
the chronological catalogue of all writings of an author, published or not, during given periods;
a record of all the alterations an author made in his texts while composing them (insertions, deletions, transpositions, and the like);
a full record of all corrections the critical editors imposed on the text;
physical descriptions of the source manuscripts;
discussions of the genealogy of each text;
explanations of how any number of textual cruxes were solved;
hyperlinked conceptual indexes;
hyperlinked navigational maps that guide users through a large maze of complicated texts; and
an expandable set of hyperlinked annotations that identify proper names, provide references to citations and quotations found in the texts, and clarify conceptual and theoretical matters discussed by the author.
Such a mass of data provides abundant research opportunities to scholars, not only in terms of text searches and information gathering, but especially also in terms of interaction and collaboration. We envision the online edition as a place where communities of serious and well-regulated inquiry can get established, within which scholarly minds are free to contribute any new enhancement they desire to the dynamic online repository put at their disposal.
The range of potential contributions includes the following sample:
additional annotations to the texts (historical, bibliographical, philosophical, mathematical, scientific, logical, etc.);
addition of descriptive and conceptual metadata to the bank of digital images of manuscripts and documents;
embedding of visual metadata within those digital images;
participation in the reorganization of documents;
creation of navigational trails across manuscripts and documents augmented with commentaries or suggestions directed toward colleagues or classrooms;
demonstrations of the existence of authorial or editorial errors and proposals for their correction;
the linked results of slow readings; textual maps displaying the structure of arguments;
cross-connections between texts; arguments supporting or undermining the dating of texts;
discussions of strengths and weaknesses of targeted passages;
discussions of the intellectual or theoretical development of ideas throughout texts;
contextualization of the author’s ideas within his or her cultural and socio-political milieu;
connections with the works of other authors; full-fledged contributions in the form of scholarly articles on specific topics of which the platform could become the depository; and so on.
Any or all of these options need technological solutions and the creation of adequate interfaces that support them while guaranteeing their integrity. They may include specialized forums and multi-threaded discussions, but they will especially offer a regulated environment with several levels of authorized access, the granting of which will be subject to the continuous assessment and peer-reviewing of the quality of a contributor’s work, the whole being supervised by an appropriately appointed board of moderators. This selective process will keep track of its rejection rate in such a way that the value of a scholar’s contributions that end up being integrated within the platform will increase, so that the platform itself may become a benchmark that meets P&T standards in verifiable and credible fashion.
Much of the work illustrated below was conducted by a team of Ph.D. and M.S. students in the HCI program of the School of Informatics, under the direction of Professor Davide Bolchini. Those students were Yuan Jia, assisted by Reecha Bharali.
The first stage in their research was to study the Peirce Project workflow, what it was all about, how STEP would be organized and what kind of materials it would feed to CORPUS for what purposes. The second stage was to conduct interview and observe how humanities researchers conduct a number of typical text-centered research activities on the computer and online.
They identified several types of routines; took notes of the sequence of actions or activities each involved; identified common types of roadblocks impeding searches, data collection, and data organization; asked interviewees what features they especially wished CORPUS to provide; and then they began designing several ideations of the platform, each one focused on a distinct set of tasks.
The first two illustrations below concisely captures a network of actions and purposes related to the types of data a platform like STEP would make available to scholars within CORPUS who seek to browse, learn, study, take notes, create content, share or discuss those contents with others, and collaborate on specific tasks.
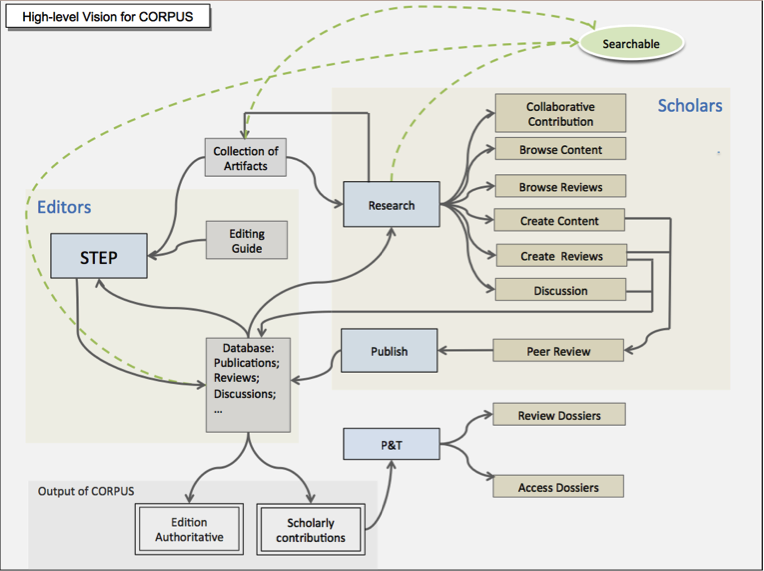
Mapping several core functions of CORPUS in relation to distinct purposes: conducting research, contributing to CORPUS, seeking accreditation for those contributions.
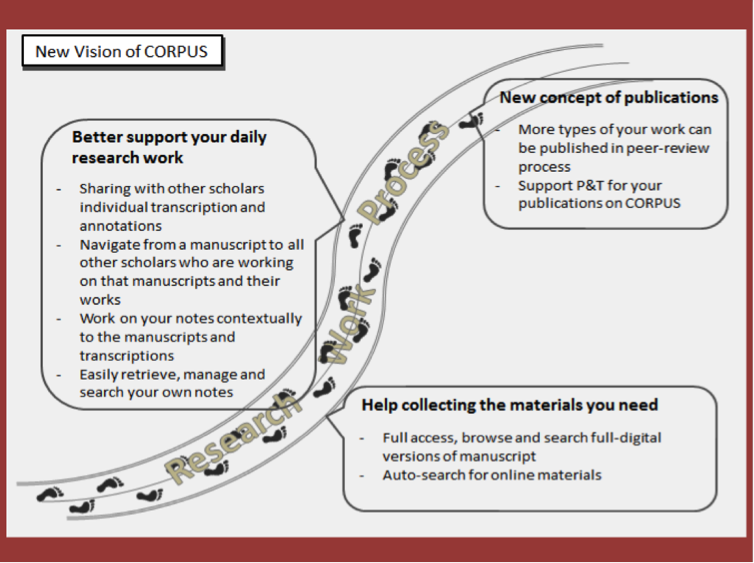
Focusing on several requisites or desiderata expressed by scholars regarding CORPUS.
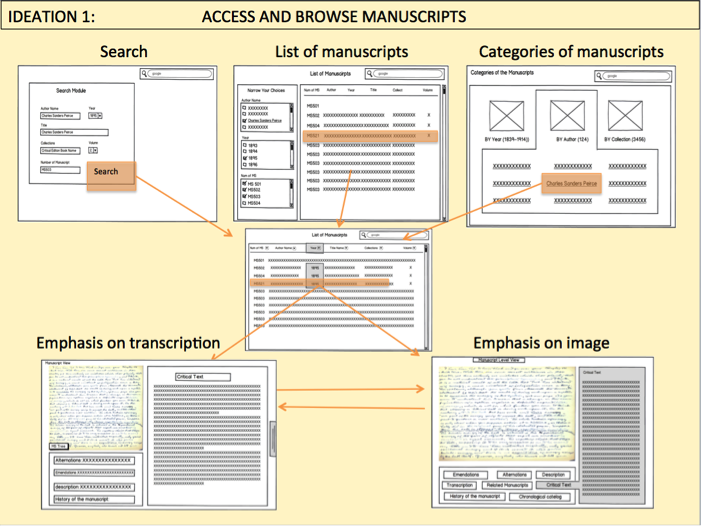
The first ideation (shown below) reflected upon and collected several key components that would be needed to design an interface facilitating access to manuscript images and their corresponding critically edited transcriptions.
The second ideation below conducted the same kind of reflection regarding an interface facilitating access to an author’s published texts and their possible links to manuscripts and other types of data available in CORPUS.

The third ideation focused on those components of CORPUS that would go into shaping up the user’s workbench: an area from where users can navigate throughout CORPUS and return to in order to initiate new projects, resume old ones, assess the status of one’s contributions, administer private and collaborative work, and so on.

A fourth ideation sought to visualize dynamic relations between key CORPUS elements, an essential step in order to understand how to organize links and relations of dependencies among databases and other components.
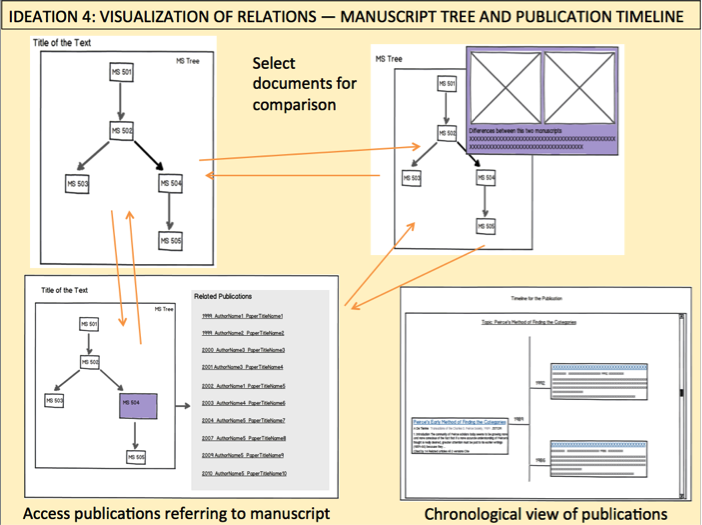
Another way of looking at those connections is shown below, this time taken from the standpoint of users accessing materials for purposes of writing, reading, contributing, sharing, and reviewing.
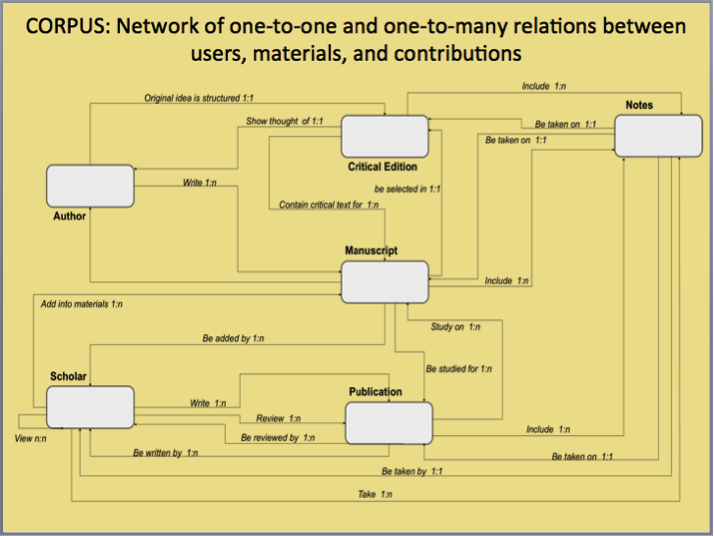
Based on all of those ideations, the HCI team then began designing ways of integrating them and consolidating them within a preliminary design of a possible CORPUS platform—i.e., a prototype of how it might look like and work like (indeed, the online prototype is dynamic and can be clicked on to move from place to another, to create notes linked to manuscripts, and to view the texts from distinct perspectives).
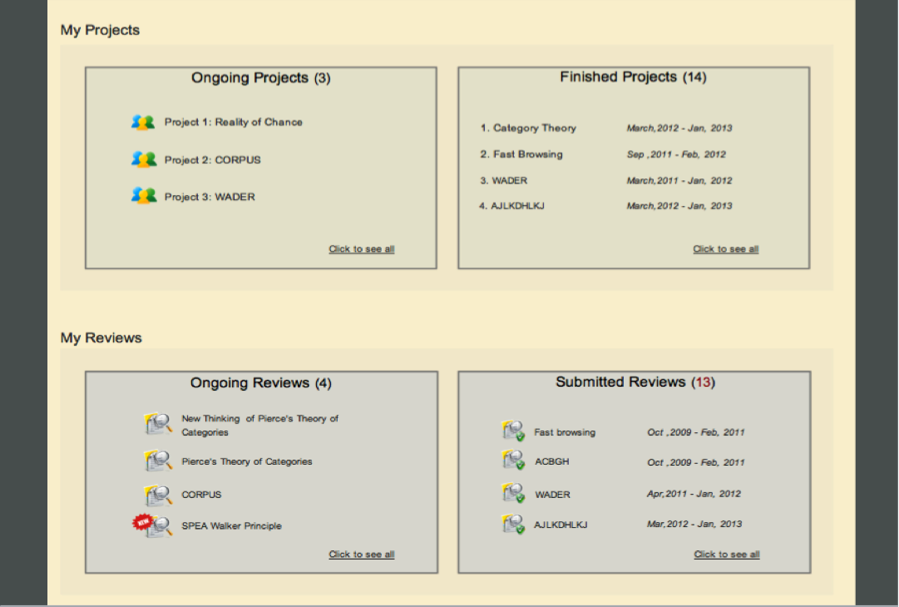
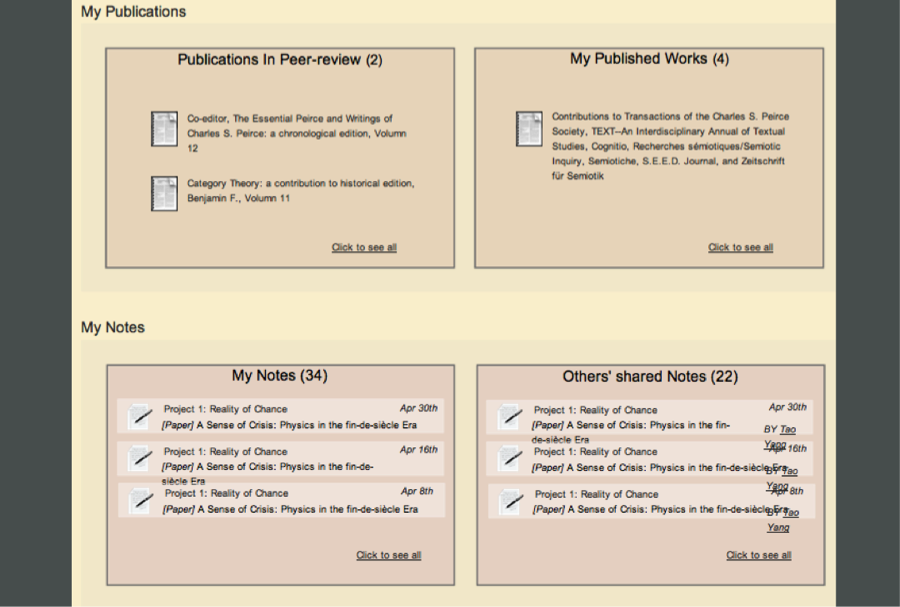
The three following illustrations show the prototype of the main work space. These are not three separate work places but just one that one scrolls through from the top to the bottom. The five main areas include “My Materials,” My Projects,” “My Reviews,” “My Publications,” and “My Notes.”
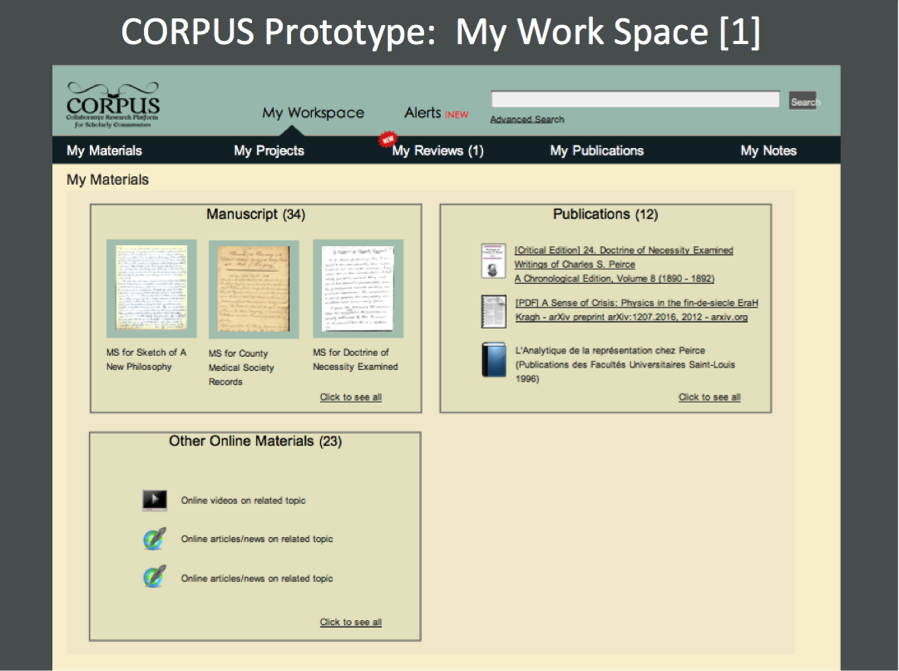
Shown below is a view of the interface component that would provide access to a manuscript image and its edited transcription, where access to the image is emphasized.
The next illustration reverses the focus, emphasizing access to the transcription itself, and bringing apparatus annotations tools under the user’s fingertips.

Finally, attention has been paid to the peer-reviewing process to be embedded within CORPUS. This is an essential incentive to encourage scholars to access and use CORPUS in a collaborative spirit of rigorous but generous scholarship, with the advantage of having one’s professionalism recognized by the community of scholars.

“Logicality inexorably requires that our interests must not stop at our own fate, but must embrace the whole community. This community, again, must not be limited, but must extend to all races of beings with whom we can come into immediate or mediate intellectual relation. It must reach, however vaguely, beyond this geological epoch, beyond all bounds.”
Charles S. Peirce cultivated a deep appreciation for well-made back-of-the-book indexes. Many of his Nation reviews end with an assessment of the book’s index. Here is a sampling:
“[Prof. Florian Cajori’s The Teaching of Mathematics in the United States] is a bulky pamphlet of 400 pages, full in facts and decidedly anecdotical, but sadly wanting an index.” (1891)
“The quarto text [of Gilbert’s De Magnete] has the advantage of an index of 23 pages.” (1894)
“[Wemyss Reid’s biography of Playfair] is altogether a difficult book to drop. The index is thoroughly well executed.” (1900)
“We may add that [Caldecott’s Philosophy of Religion in England and America] is a very agreeable book to read. Its excellent index compensates for all faults of classification.” (1901)
“The index [in Vallery-Radot’s Life of Pasteur] is excellent, notwithstanding a few misprints.” (1902)
“The index is like the book itself [Gidding’s Inductive Sociology]. It is not perfect; but it is much more than pretty good.” (1902)
“We should have preferred an alphabetical index to the analytical table of contents that is furnished [in Flint’s Philosophy as Scientia Scientiarum]. (1905)
“The index [in Roscoe’s autobiography], on the other hand, is so meager as to be almost worthless.” (1906)
Every volume of a critical edition comes of course with a comprehensive index. The first requirement for a scholarly index is that the indexer fully understands the texts to be indexed. In Peirce’s case, this means that the indexer has to be a Peirce scholar. No professional indexer, no matter how skilled and experienced, will do if that person does not understand the intricacies of the Peirce text. Indexing a text is indeed not at all limited to simply selecting certain words or phrases from it and attaching a page number to them. A competent indexer needs to be able to read the text between the lines, so as to identify whether any particular sentence or paragraph is providing a definition (without necessarily saying so), a positive argument, a counter-argument, an objection, an allusion, a suggestion, a firm conviction, an hypothesis, a demonstration, a proposition the author is actually agreeing or disagreeing with, a complete or incomplete statement, a stage of inquiry, a firm or a tentative conclusion, and so on. The indexer must be able to map out the development of an analysis from beginning to end in order to construct entries, subentries, and cross-references that reflect accurately the evolving conceptual structure across all pages of a volume. Consistency of terminology, depth of analysis, sense of the concise formula, and constant attention to what words or phrases index users are likely to be looking for, are indispensable skills as well. Indexing a volume of Peirce texts is very hard work, and requires extraordinary competence, so much so that there is no doubt that a serviceable and reliable index is a vital contribution to scholarship as significant as a research paper in a first-tier journal. Indeed, it is simply impossible for any computational-linguistics-based indexing software to parse a text as complex as Peirce’s and produce an index as excellent and trustworthy as one produced by a specialist of the author that also happens to be good at indexing—a rare combination, one must admit, but indispensable all the same.
The main difficulty, of course, is the perceived drudgery of the sustained exercise. Indexing a full volume of the Peirce edition easily takes two to three months working full-time. Keeping track of all entries and subentries, checking one’s work all the time, revising entries, inserting new ones, alphabetizing everything correctly according to a consistent scheme, keeping the page numbers in right order, checking cross-references, verifying the consistency of cross-postings, dealing with sudden changes to the text’s pagination, verifying spelling, researching the full proper names of persons only referred to by their last names, all of these tasks and subtasks can be quickly overwhelming or at least severely brain-taxing.
How do we deal with this challenge at the Peirce Project? We have developed our own solution over the last 25 years. It so happens that the Peirce Project has adopted Apple Macintosh as its principal computer platform since 1986. In the 1980s and 1990s, there were no indexing software that worked on the Mac. All there was was Cindex, a then fledgling indexing software that only worked on a PC, and very poorly at that. At some point, André De Tienne was given the task to index the volumes of the edition, starting with volume 5. He decided then and there that he would use all the spare time he could manage to develop an indexing program that would work on the Mac. Pretty soon the software was born, and he called it HyperIndex, because it was made with HyperCard, a free IDE that came with every Mac. HyperIndex became over the years a sophisticated software that could do plenty of things that Cindex and other PC solutions could not. Many Mac-loving professional indexers in the US and abroad bought HyperIndex. But then came a time when Apple stopped supporting HyperCard, and then moved to an Intel solution that could no longer support Mac Classic software. And so HyperIndex, with which De Tienne indexed volumes 5, 6, 8, and EP2, fell into obsolescence.
When volume 9 began nearing completion, De Tienne surveyed current indexing software (including a much modernized Cindex—still the lead indexing software nowadays), downloaded demos, tried them, and became much disheartened. None of them could do what HyperIndex could do. And so De Tienne decided to reprogram his indexing software from scratch, using a new IDE for the purpose, one engineered to be cross-platform (Mac, Windows, and Linux). It took many nights and weekends to build that software. And so it came that LiveIndexer was born—a terrific piece of software that not only can do everything that HyperIndex could do, but also a whole lot more, at much greater speed, and in six different languages.
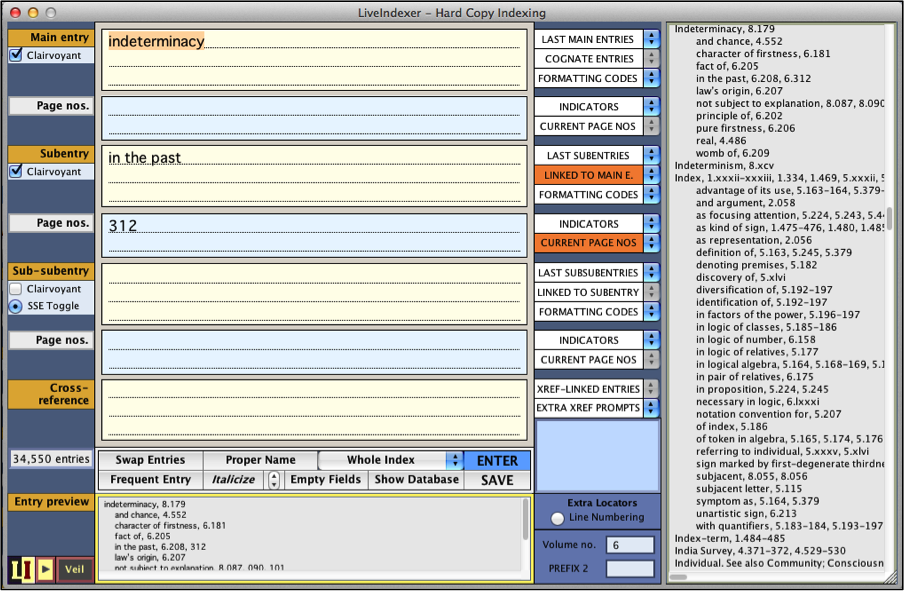
LiveIndexer is a dedicated back-of-the-book indexing software for the use of professional, academic, and occasional indexers. It is full-featured, easy to learn, customizable, and adapted to the following six languages: English, French, German, Italian, Portuguese, and Spanish. Anyone in need of indexing a scholarly book, a dissertation, a journal, a report, a legal brief, a manual, a textbook, or even a multi-volume collection will find LiveIndexer a time-saver offering a trustworthy high-quality end product. So will indexers who want to extend the range of their indexing activities and services beyond traditional book indexing.
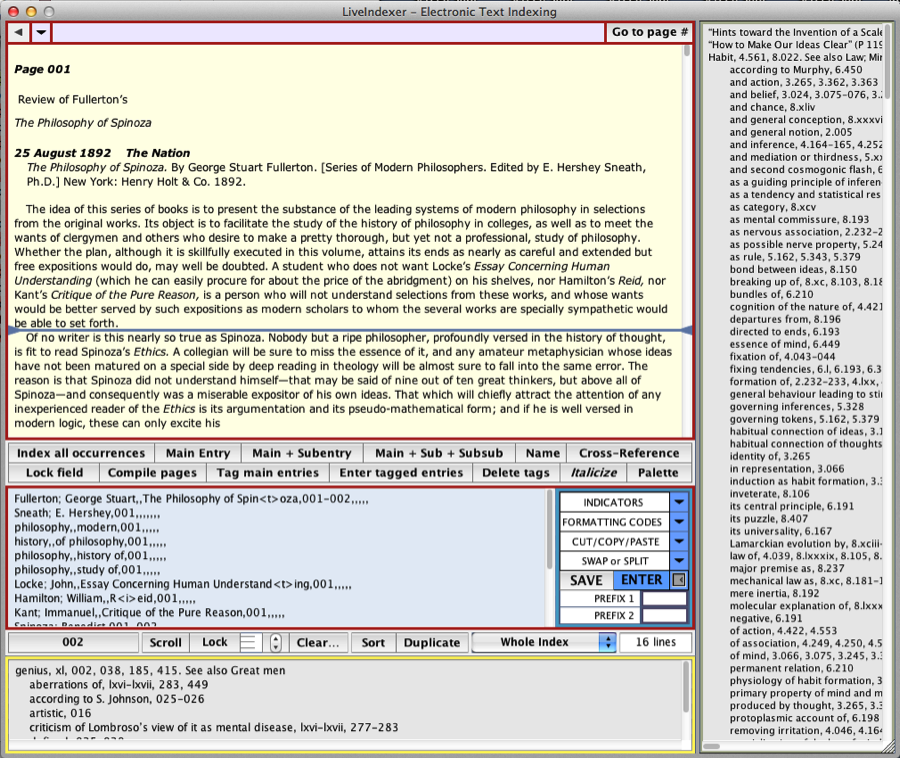
LiveIndexer can be used to index either hard copies or imported electronic texts. It provides two distinct interfaces allowing indexers to enter entries, subentries, sub-subentries, and cross-references either by typing them (while minimizing typing in multiple ways) or by selecting or clicking or tagging them directly in the text. LiveIndexer does not accommodate sublevels beyond sub-subentries because they are unhelpful to index users, inconvenient to typeset, and not recommended by leading manuals of style. LiveIndexer provides the user with full control of every aspect of index-making while doing the tedious work of keeping track of all entries, sorting them according to various sets of rules, and laying them out according to different standards. The software provides many tools that ensure consistency and accuracy by ensuring the regular formatting of entries, checking cross-references, avoiding redundant entries, correcting faulty numbers, pinpointing errors, and offering constant previews of how the index is shaping up.
As a dedicated indexing software, LiveIndexer (currently in version 2.0) offers efficiencies that far surpass opaque index-tagging protocols offered in word processors and other text-design software. What distinguishes LiveIndexer from its peers is the following collection of features:
De Tienne recently decided to donate LiveIndexer to the Peirce Edition Project. The idea is simple: LiveIndexer can be purchased by anyone in need of an indexing software, whether for a one-time book or to make a living. All proceeds beyond overhead costs are integrally turned over to the Peirce Project to support the edition. Such support goes for instance to pay the salary of those graduate students we hire and train as research assistants.
For complete information regarding all the features of LiveIndexer, you may download the 25-page LiveIndexer PDF here.
LiveIndexer has been used successfully to index volume 9 of the edition. And it has also been used successfully to combine the indexes of volumes 1 to 6 and 8 into one comprehensive multi-volume index. It is with great pleasure that we are making this multi-volume index available to you. Click here to download its PDF.
“There is a rule of good writing higher than Ciceronian purity, that of expressing your thought, both accurately and concisely. More than a rule of good writing, this is a fundamental condition of scientific thinking; for man cannot think at all without formulas, nor think powerfully without concise formulas.”
PithMaker™ was created by André De Tienne, the director of the Peirce Edition Project. Its direct use for the Project is to feed the widget “Peirce’s Pith” on the Project’s website with aphorisms picked randomly from a large collection of pithy statements culled from Peirce’s writings.
PithMaker is a utility that makes it easy to create, collect, edit, and maintain, lists of aphorisms, sayings, notable succinct quotations, adages, apothegms, mottoes—in short any sort of pithy statement that can be attributed to an author within a particular year or range of years. This is one of the most useful and effective ways to promote a great author or thinker. It provides enormous inspiration and abundant food for thought. It also creates, sustains, and revitalizes interest in a website.
And indeed, one practical purpose of PithMaker is to enable users to share those collections on their own scholarly website (whether that of a scholarly edition, a research center, an academic department or personal page, and the like). PithMaker automatically transforms your lists of aphorisms into a Javascript (.js) document that you can export to a server or integrate within a webpage script.
When clicking the “Example” button anywhere in PithMaker, users have access to 650 aphorisms by Peirce taken from that collection. While in Example mode, users can test all fields and buttons and learn how PithMaker works in its three adjoining interfaces (or “cards”) by playing with that collection. Clicking the “Example” button again turns it off, allowing you to begin or resume your own aphorism collection.

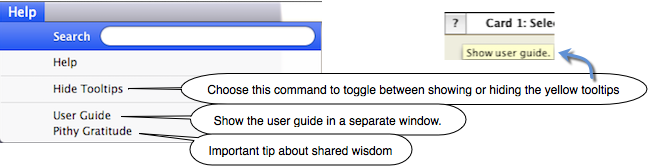
A help menu was created to assist users with any problems using PithMaker.
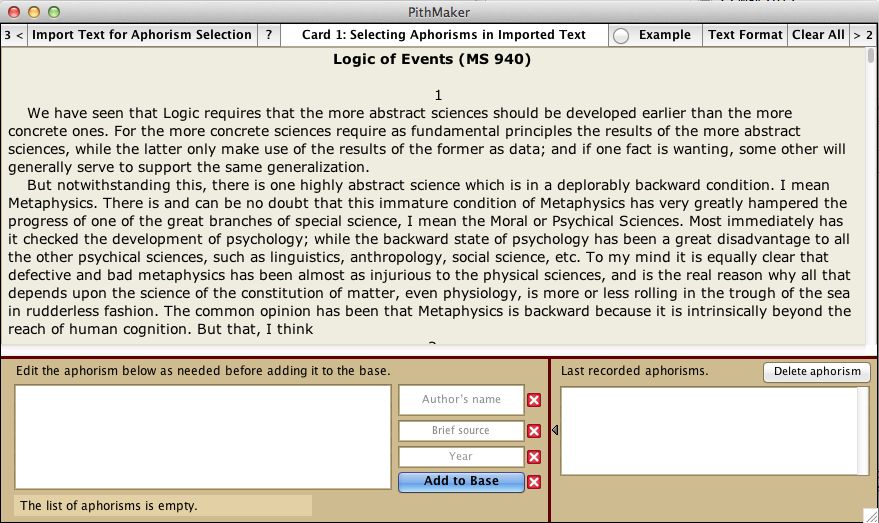
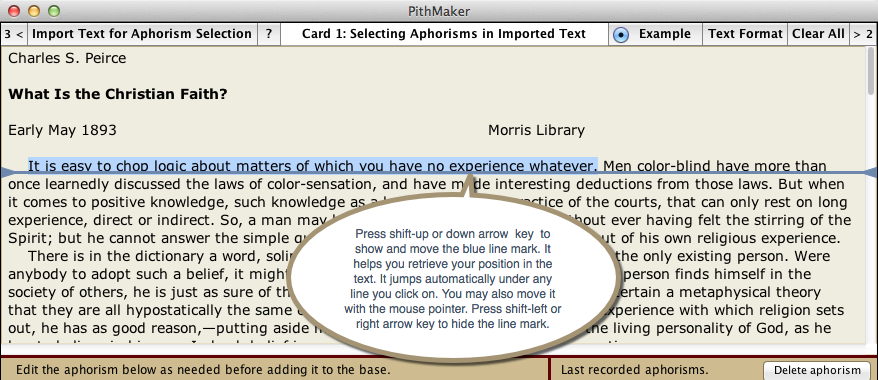
Card 1 in PithMaker allows you to import any text from an author and select aphorisms within that text.
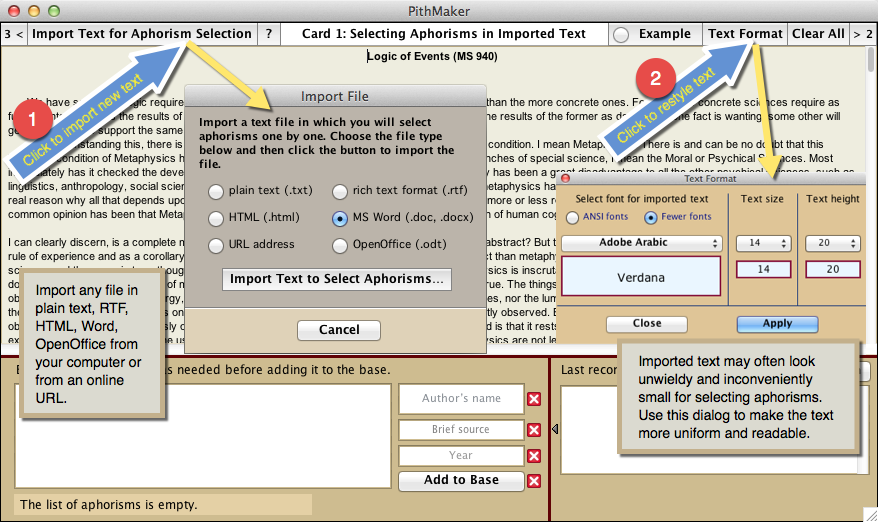
To import a text, click the button “Import Text for Aphorism Selection.” A dialog will give you the choice between plain text, RTF text, HTML text, URL address, Microsoft Word text, or OpenOffice text. Choosing “URL” allows you to download an online text from which you can cull aphorisms.
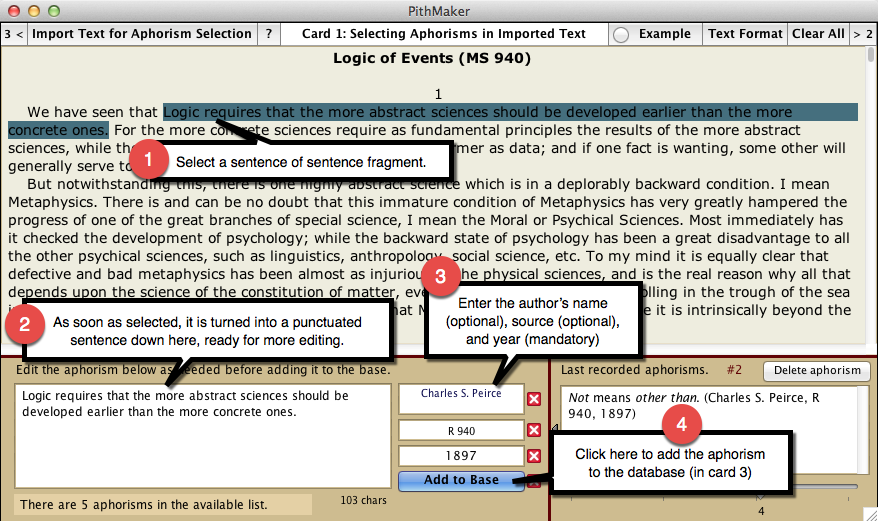
Using the mouse pointer, drag through any series of words to highlight it. As soon as you release the mouse button, that highlighted series gets pasted in a field underneath the text, with its initial character capitalized, and its ending punctuation provided if there was none in the selection. You edit that series of words as needed, provide a date (a year of some sort) for it, optionally the name of the author, optionally a brief bibliographical source (brief to avoid cluttering the space underneath the displayed aphorism), and then hit the return key or click the “Add to Base” button. The aphorism is then added to the database accessible in Card 3.


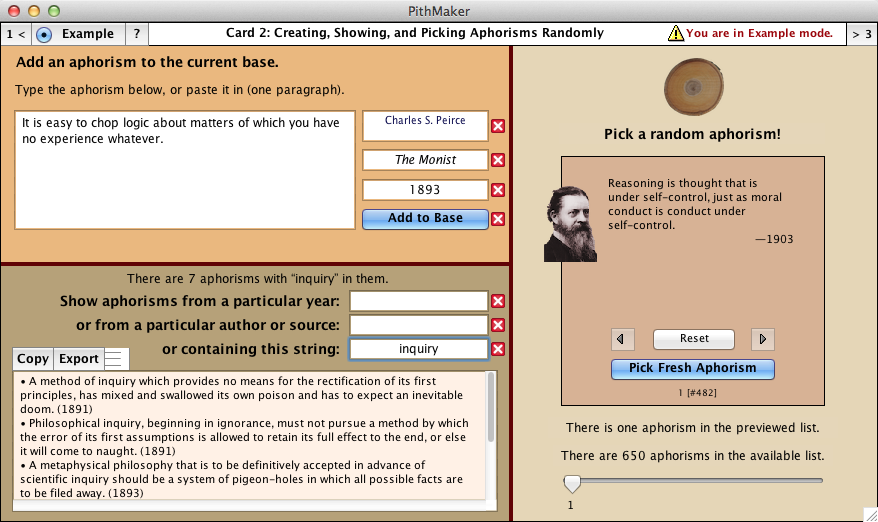
Card 2 in PithMaker allows you to perform three activities:
Users can type aphorisms manually and add them to their collection (when working from a book or a hard copy because the text cannot be imported into PithMaker). You create your aphorisms in rich text format and PithMaker will convert it into HTML. HTML is preferred because it retains such things as italics and boldface.

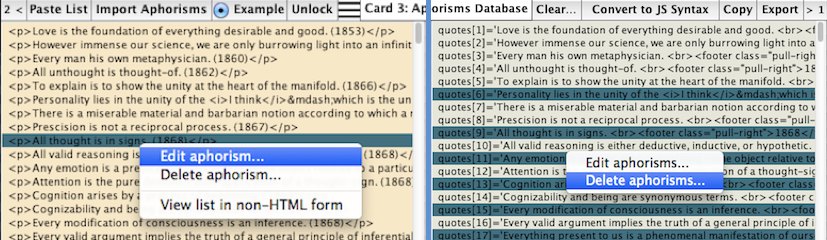
Users can search the collection of aphorisms by year of composition, by author, by source, or by a particular string of characters. Right-clicking the results field allows you, via a pop-up menu, to edit or delete aphorisms at once in that field and in the database.

Users can play with a utility that picks aphorisms at random in the available collection and displays them according to a standard format (the format dictated by the javascript of Card 3). The utility always picks a fresh aphorism, avoiding duplication. Users can navigate through previous random pickings. Option-clicking the “Pick Fresh Aphorism” button allows you to display an aphorism on the basis of its numbering in the collection.

Card 3 in PithMaker is where the database resides.
The field on the left side contains the aphorisms as you have entered them. Aphorisms are entered in that field in FIVE ways.
By pasting a list of aphorisms copied from some other file into it. Use the “Paste List” button (top left of Card 3) to do so.
By importing a file using the button “Import Aphorisms.” A dialog will give you the choice between plain text, RTF text, HTML text, URL address, Microsoft Word text, or OpenOffice text. Choosing URL allows you to download an online file into PithMaker. One good way of importing an HTML text is by typing a list of aphorisms into Microsoft Word, export it as HTML, and either importing that file into PithMaker, or copying it and pasting it into PithMaker. Either way, the imported or pasted-in document will usually display very complex HTML. As soon as you click the “Convert to JS Syntax” button, that HTML will be instantly simplified.
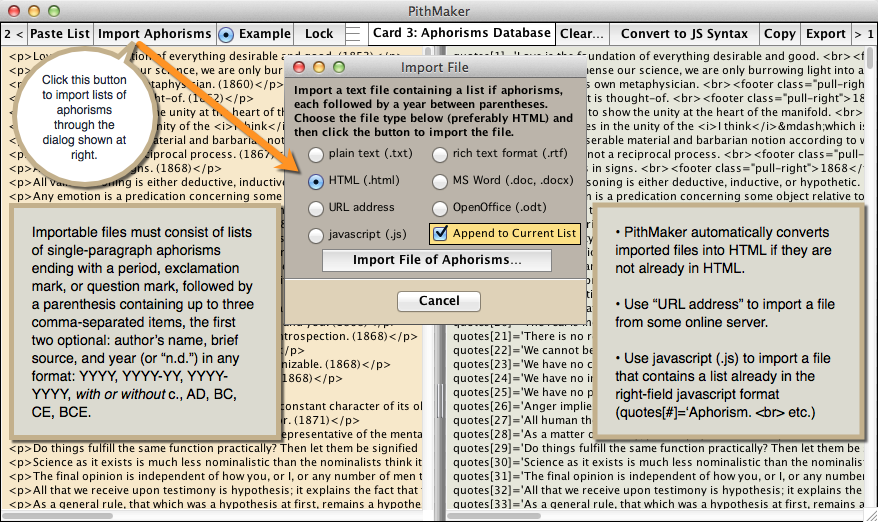
By using Card 1 in PithMaker (see above).
By using the first feature in Card 2 (manual typing).
By typing directly into the left field, making sure to respect the syntax: each aphorism must be one paragraph long, and end with a period followed by a space, an open parenthesis, an optional name followed by a comma and a space, an optional abbreviated bibliographical source, and a year or year range (YYYY, YYYY-YYYY, YYYY-YY), optionally preceded or followed, as the case may be, by c. (for circa), AD, A.D., BC, B.C., CE, C.E., BCE, B.C.E., and finally a closing parenthesis. If typing, do so in regular rich text, not HTML. In the event you were mixing HTML text with non-HTML text, PithMaker will sort it out and turn the non-HTML aphorisms into HTML aphorisms.
PithMaker treats the aphorisms in HTML form in order to preserve special characters and formatting. You can view them in non-HTML form by right-clicking the field and choosing “View in non-HTML form” in the pop-up menu. To return to HTML view, right-click the field again and choose “View in HTML form” in the pop-up menu.
The javascripted form of the aphorisms collection is created by clicking the button “Convert to JS Syntax” at the top right of Card 3. Doing so automatically displays the HTML form of the aphorisms in the left field. The javascript form is simple and is geared toward displaying each aphorism within a webpage widget according to the following general form:
Aphorism text that is striking, succinct, substantial, and a life lesson for all readers.
Example:
quotes[1]='Love is the foundation of everything desirable and good. <br><footer class="pull-right">Charles S. Peirce, W1: 4, 1853</footer>'
Love is the foundation of everything desirable and good.
Click the “Export” button (top right of Card 3) to export the content of either the left or the right field to a file.
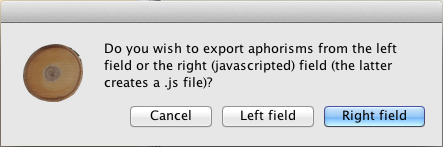
Exporting the content of the left field creates a text or RTF file of it.
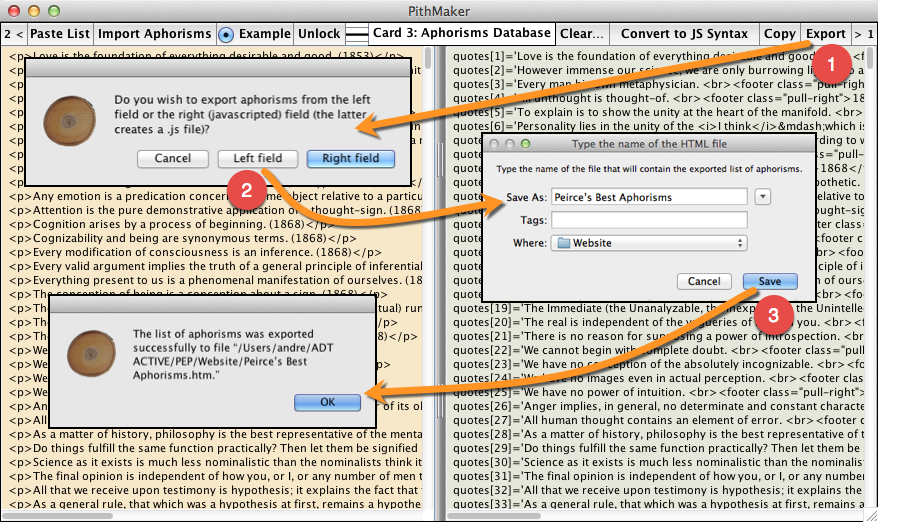
Exporting the content of the right field automatically creates a javascript (.js) file. In the latter case, a dialog will allow you to renumber all the aphorisms as needed.
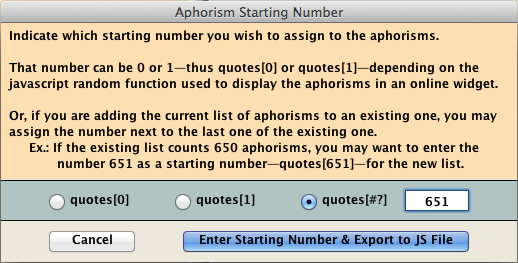
The default number of the first aphorism is 1 (“quotes[1]”). But you may want to have the list start from 0 (“quotes[0]”) if the javascript randomizing function you want to use starts from 0. Or you may want to add the exported list to an existing list, and therefore you may want the starting number to be (the number of entries in the existing list) + 1. If you already had 650 aphorisms, for instance, you may have the new list start at 651 in the appropriate dialog box, thus inserting “quotes[651]” at the start of the first new aphorism.
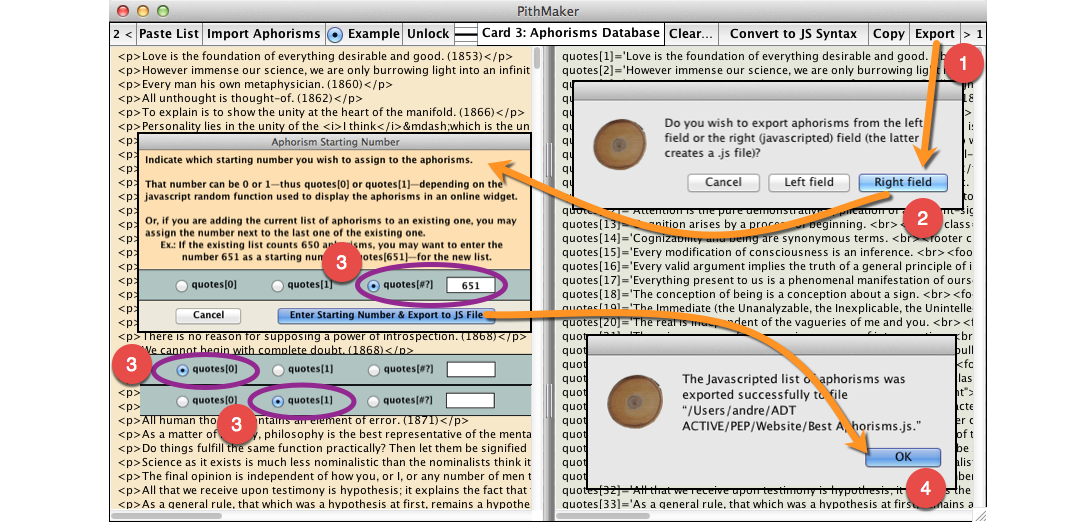
Clicking any line in either field automatically highlights the corresponding line in the other field. The “Lock/Unlock” button above the left field unlocks it so users can type into it, and locks it so users can click the lines. The iconic button to the right of the “Lock/Unlock” button shows the status of the field: unlocked (halved lines), single-line selection (one thick line and two thin lines), and multiple-line selection (three thick lines). You can click it to toggle between single-line and multiple-line selection (in both fields at once).

When right-clicking one or more selected lines, a pop-up menu shows up that allows you to either delete them or edit them. If you choose to edit them, they will be displayed in a separate dialog where you make the modifications, which will then be carried out in both fields at once.
Please make a donation to the Peirce Edition Project. Click the “Donate to PEP” button on the left side of the screen. You will reach Indiana University’s “Make a Gift” form (by clicking here). Type “Peirce Edition Project Annual Fund” in the “Search all funds” box, then choose its name in the field that pops up right underneath. Click the “Next” button. Type a donation amount in the donation box. Under “Gift in honor of,” type “PithMaker” so that we know what prompted your act of generosity. Continue following the donation site's instructions. We will thank you for your donation. That donation helps us pay for all sorts of expenses, principally the meagre salaries of students interning at the Peirce Project and who get training in philosophical and editorial scholarship of the highest kind. Thank you so much!
There are two versions of PithMaker, one for the MacOS (it runs on any MacOS, whether the machine is a PowerPC or Intel-core), and the other for Windows (it runs on any version of Windows up to Windows 8). The two versions provide identical functionalities and work in the same way.
Click one of the two buttons below to download the software installer. Version 1.1 released June 22, 2015.
Double-click the installer and follow instructions. Install the application preferably inside the Documents folder. The Installer should do so automatically.
Once the software is installed, open the folder “PithMaker 1.1,” and within it a second folder named “PithMaker” or “PithMaker for Windows.” Double-click the application’s icon (a slice of a tree trunk, the center core of which is called “pith”). A PithMaker splash screen will come and go quickly, and then the application will come into view.
In Windows, if the installer file or folder appears in green letters in the directory, that's because it remains encrypted. Right-click it, choose “Properties” at the bottom of the pop-up dialog, click the “Advanced...” button under the “General” tab, uncheck the checkbox “Encrypt contents to secure data,” then click OK. This will unencrypt the file, and the filename will turn black.
For all other details, please read the User Guide (accessible through the Help menu in PithMaker), or refer again to this webpage.


